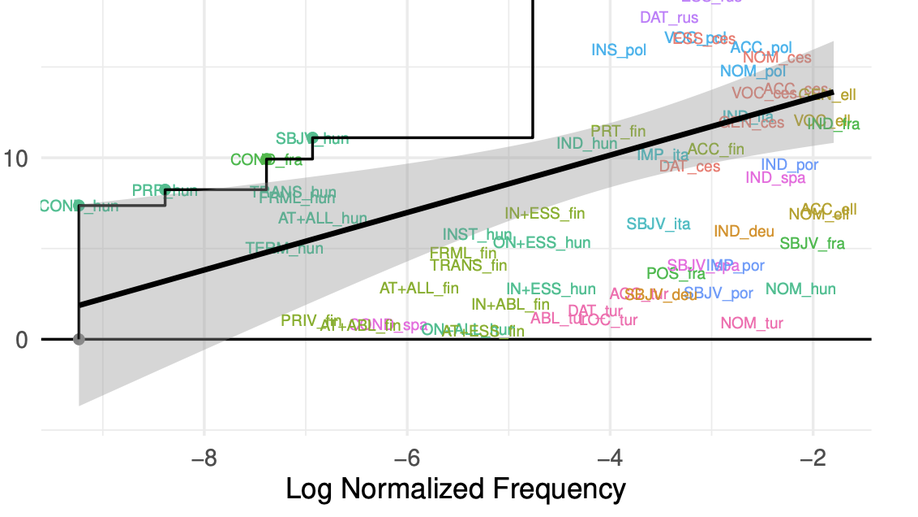
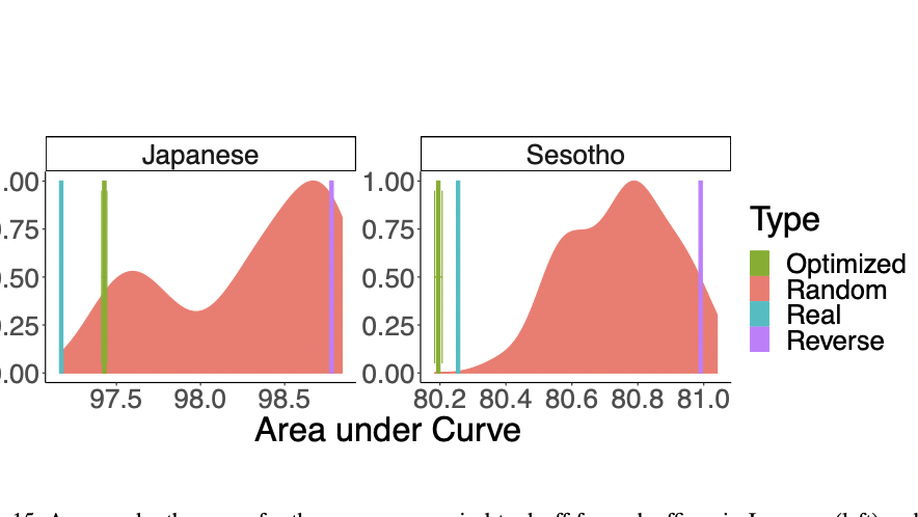
Linguistic typology generally divides synthetic languages into groups based on their morphological fusion. However, this measure has long been thought to be best considered a matter of degree. We present an information-theoretic measure, called informational fusion, to quantify the degree of fusion of a given set of morphological features in a surface form, which naturally provides such a graded scale. Informational fusion is able to encapsulate not only concatenative, but also nonconcatenative morphological systems (e.g. Arabic), abstracting away from any notions of morpheme segmentation. We then show, on a sample of twenty-one languages, that our measure recapitulates the usual linguistic classifications for concatenative systems, and provides new measures for nonconcatenative ones. We also evaluate the long-standing hypotheses that more frequent forms are more fusional, and that paradigm size anticorrelates with degree of fusion. We do not find evidence for the idea that languages have characteristic levels of fusion; rather, the degree of fusion varies across part-of-speech within languages.